Teaching AI to Fight: Q-Learning in a Browser-Based 3D Arena
Teaching AI to Fight: Q-Learning in a Browser-Based 3D Arena
What happens when you put two AI agents in a 3D arena and let them figure out how to fight? This is the story of building Human Movement Arena — a browser-based fighting game where AI learns combat strategies from scratch through reinforcement learning.
Try it yourself — play against the trained AI or watch two AIs fight in real-time.
The Idea
I wanted to see if a simple Q-learning algorithm — no neural networks, no GPU, just a lookup table — could learn to fight in a real-time 3D environment. Not in a simplified grid world, but in a proper 3D arena with skeletal animations, physics-based hit detection, and real-time combat mechanics.
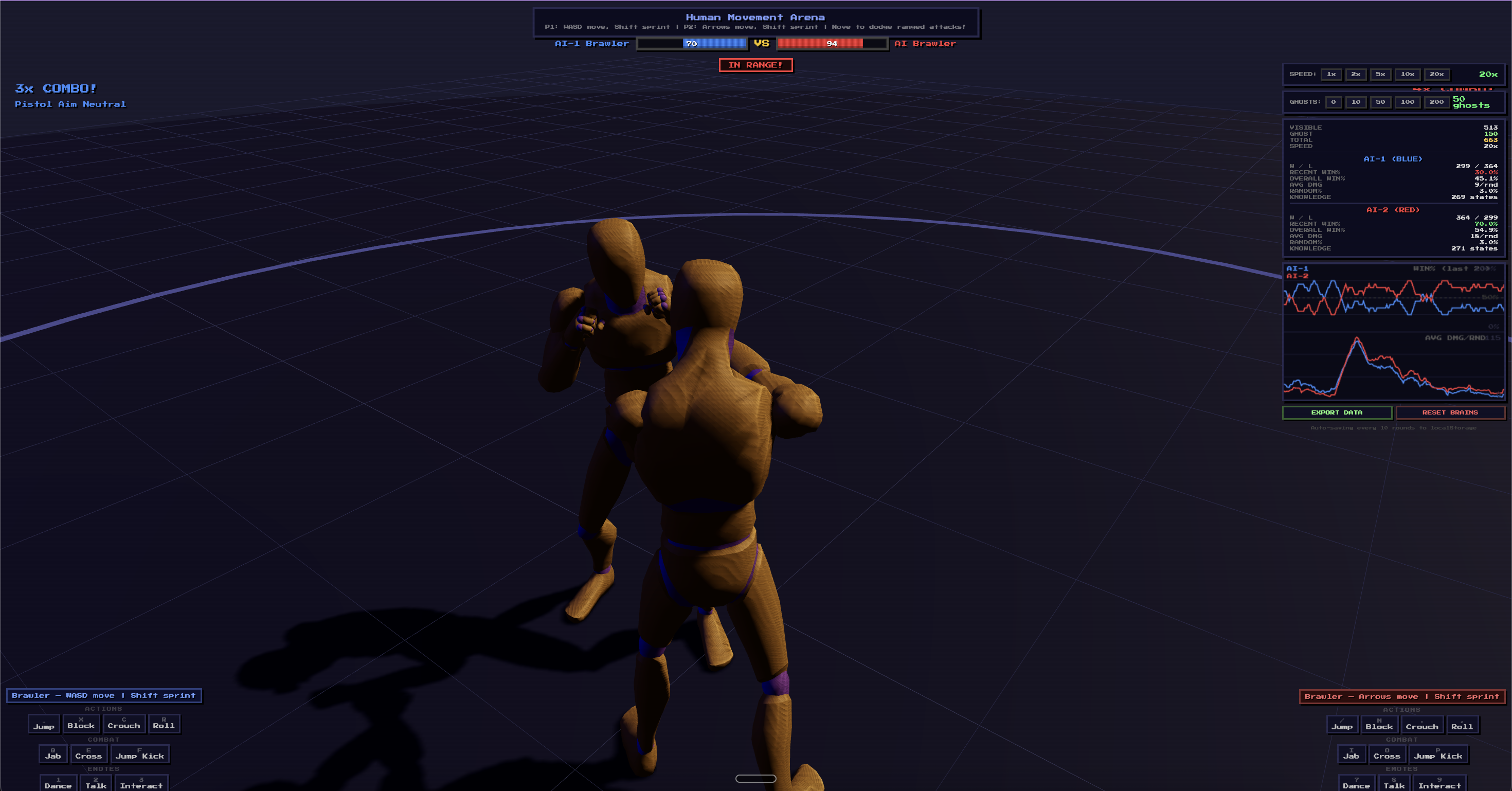
The entire system runs in a browser using Three.js. No Python backend, no ML frameworks, no GPU servers. Just vanilla JavaScript and a Q-table.
How It Works
The State Space
The AI sees the world as 6 numbers:
- Distance to opponent (close / mid / far)
- My health (low / mid / high)
- Opponent's health (same)
- What opponent is doing (idle / attacking / stunned / moving)
- What I'm doing (idle / attacking / blocking / stunned)
- Is opponent blocking? (yes / no)
That's 864 possible states. In practice, the AI explored about 350 of them.
The Actions
Seven choices every 0.1 seconds:
- Rush attack — sprint forward and swing
- Attack — swing from current position
- Block — hold guard
- Advance — walk toward opponent
- Roll — dodge forward
- Counter — block briefly, then counter-attack
- Retreat — step back
The Learning
Standard Q-learning with experience replay. After each fight, the AI replays 50 random past experiences to reinforce learning. Exploration starts at 50% random and decays to 3% as it learns.
The Experiment: What Worked and What Failed
This wasn't a clean, linear path. It took five major iterations of the reward function and three completely different training approaches before the AI could fight properly.
Phase 1: Ghost Simulation (5,050 rounds) — FAILED
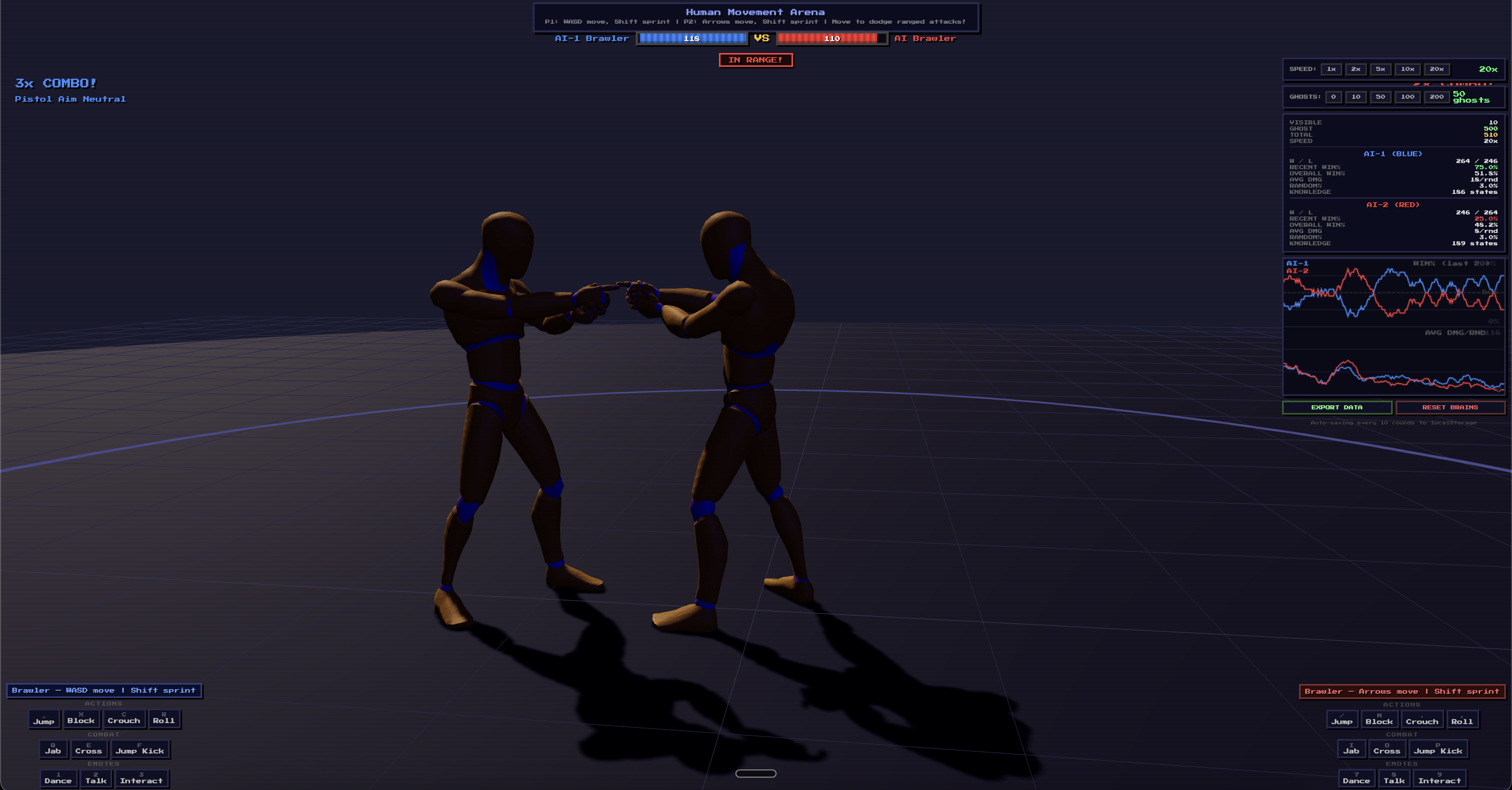
My first idea was to speed up training by running simplified 1D simulations in parallel. Between each visible 3D fight, 200 "ghost" fights would run using point-based physics. Surely more data = better AI?
Wrong.
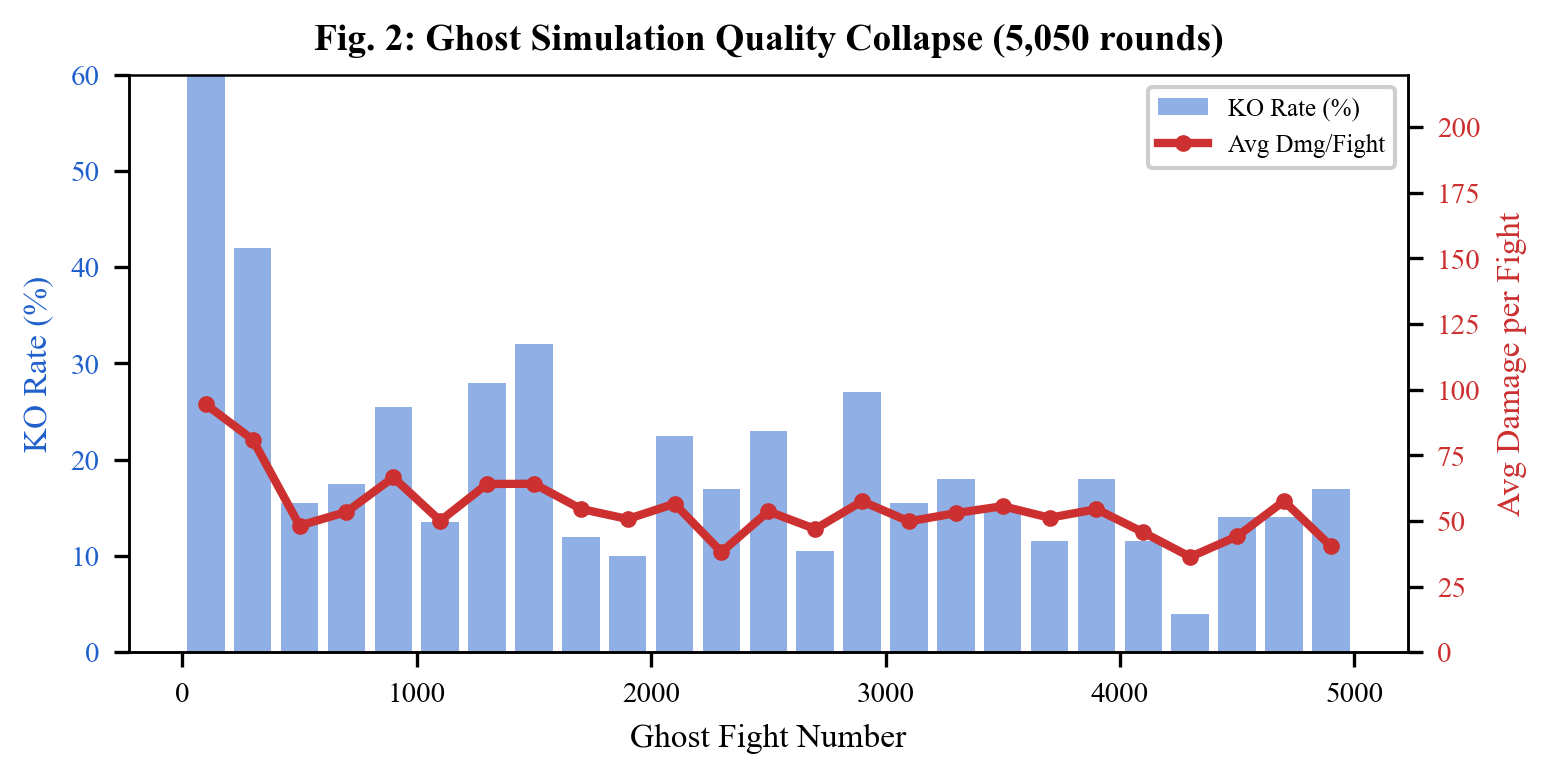
The ghost fights collapsed. Damage per fight dropped from 196 to 16 as the AIs learned to exploit the simplified physics — they could dodge everything by just moving sideways in 1D. The "strategies" they learned were useless in the real 3D game.
The key insight: 185 rounds of real 3D training beat 5,050 rounds of fake simulation.
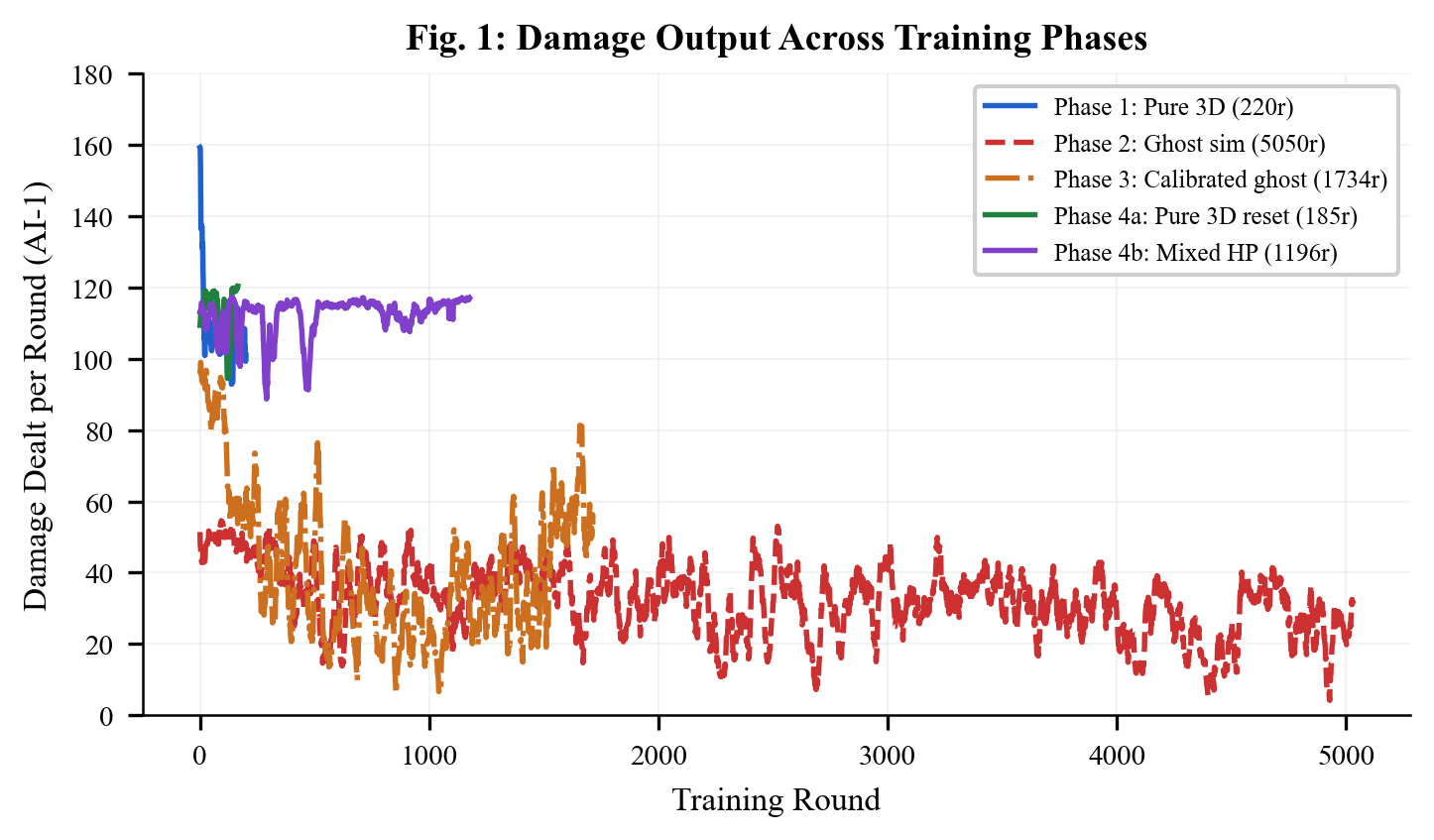
Phase 2: Pure 3D Training — WORKED
I abandoned the ghost simulation entirely and trained only in the real 3D environment. With speed multiplier (20x), turbo mode (multiple ticks per frame), and hyper mode (skip rendering), I could run hundreds of rounds in minutes.
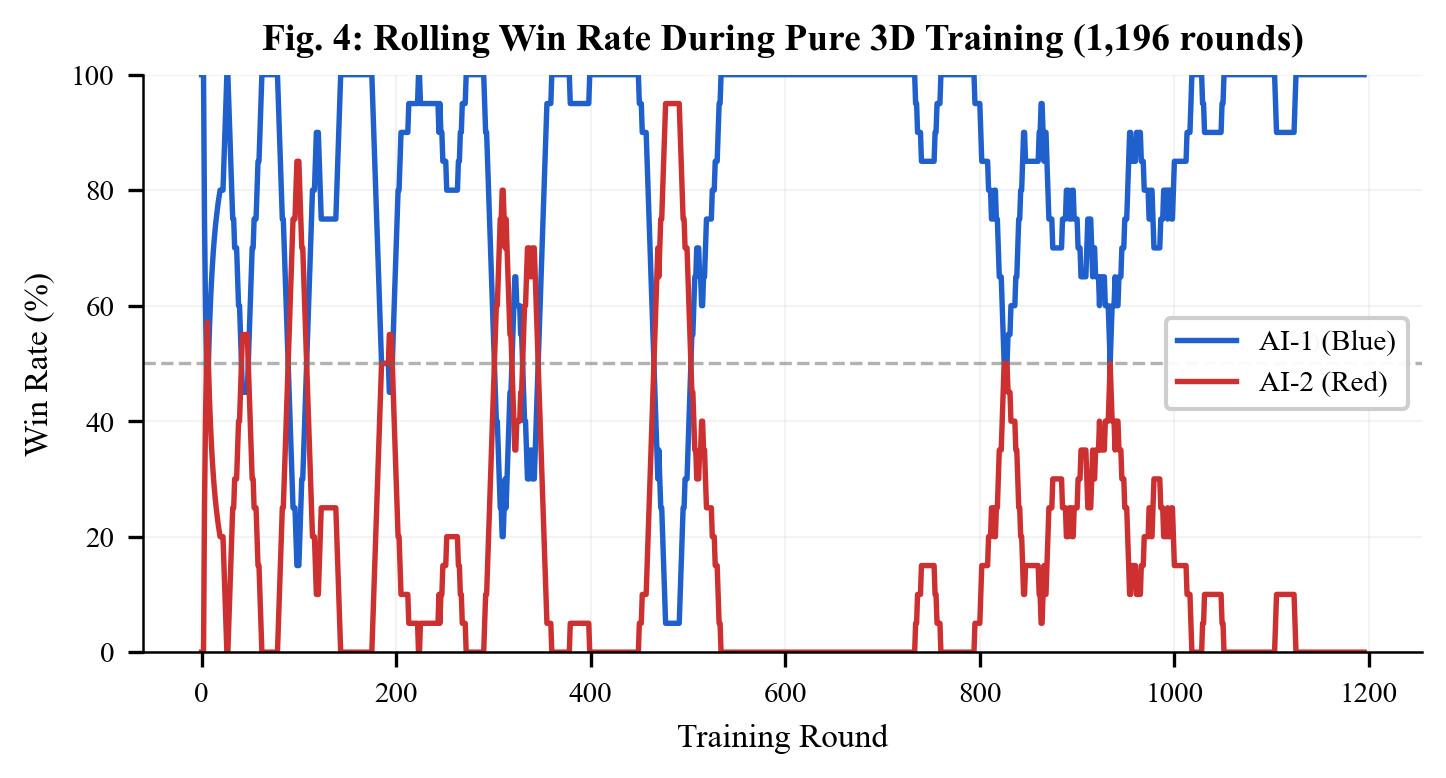
Results after 1,196 rounds:
- AI-1 achieved 84% win rate against AI-2
- 349 unique states explored (highest coverage)
- Damage per round stayed stable at ~115 (never collapsed)
- Full HP state coverage — the AI learned different strategies for different health levels
Five Ways the AI Broke (Reward Engineering)
The Q-learning algorithm itself was fine. The hard part was telling it what to learn. Five times the AI found degenerate strategies by exploiting the reward function.
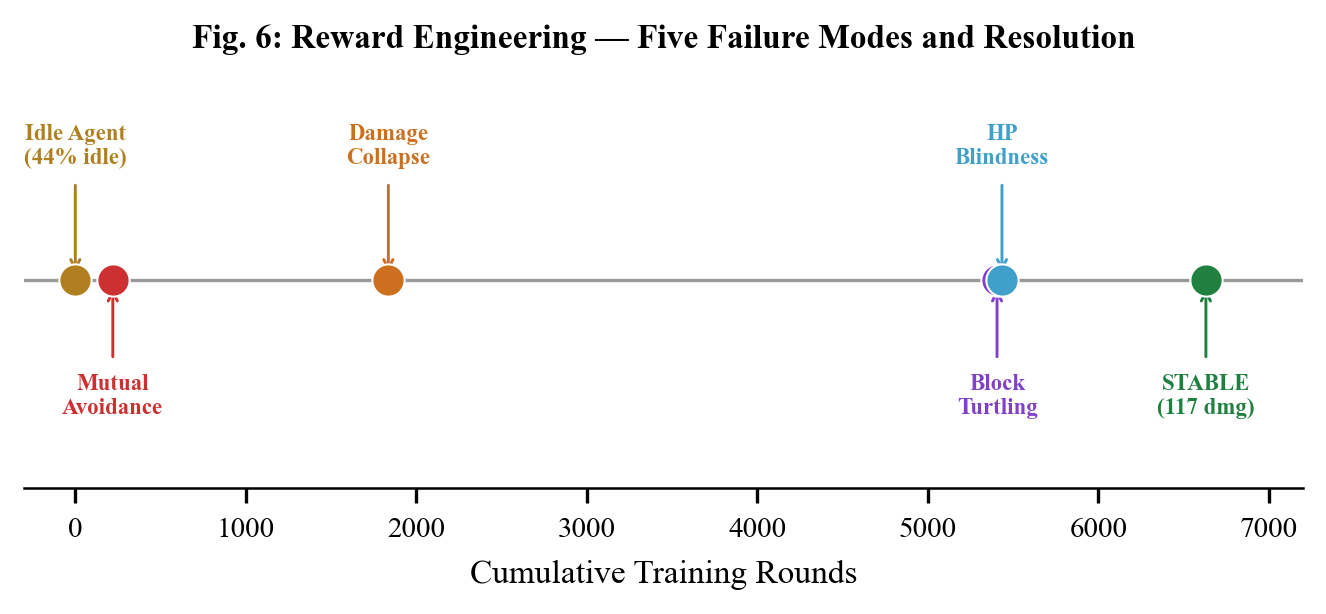
1. The Idle Agent
The AI stood still 44% of the time when being attacked. Fix: -5.0 penalty for getting hit while idle.
2. Mutual Avoidance
Both AIs stayed as far apart as possible. 99% of ghost fights timed out. Fix: Tighter arena, timeout penalty.
3. Damage Collapse
Average damage fell from 196 to 16 per round over 5,000 ghost fights. Fix: Abandoned ghost simulation.
4. Block Turtling
The AI held block for 94% of the match, absorbing chip damage but never attacking. Blocking gave +5 reward — the AI maximized this by blocking forever. Fix: Changed block reward from +5 to -1.
5. HP Blindness
Training at 10% HP meant the AI only explored 41 of 864 possible states. Fix: Randomized starting HP.
Playing Against the AI
After training, I played against the AI. The progression was dramatic:
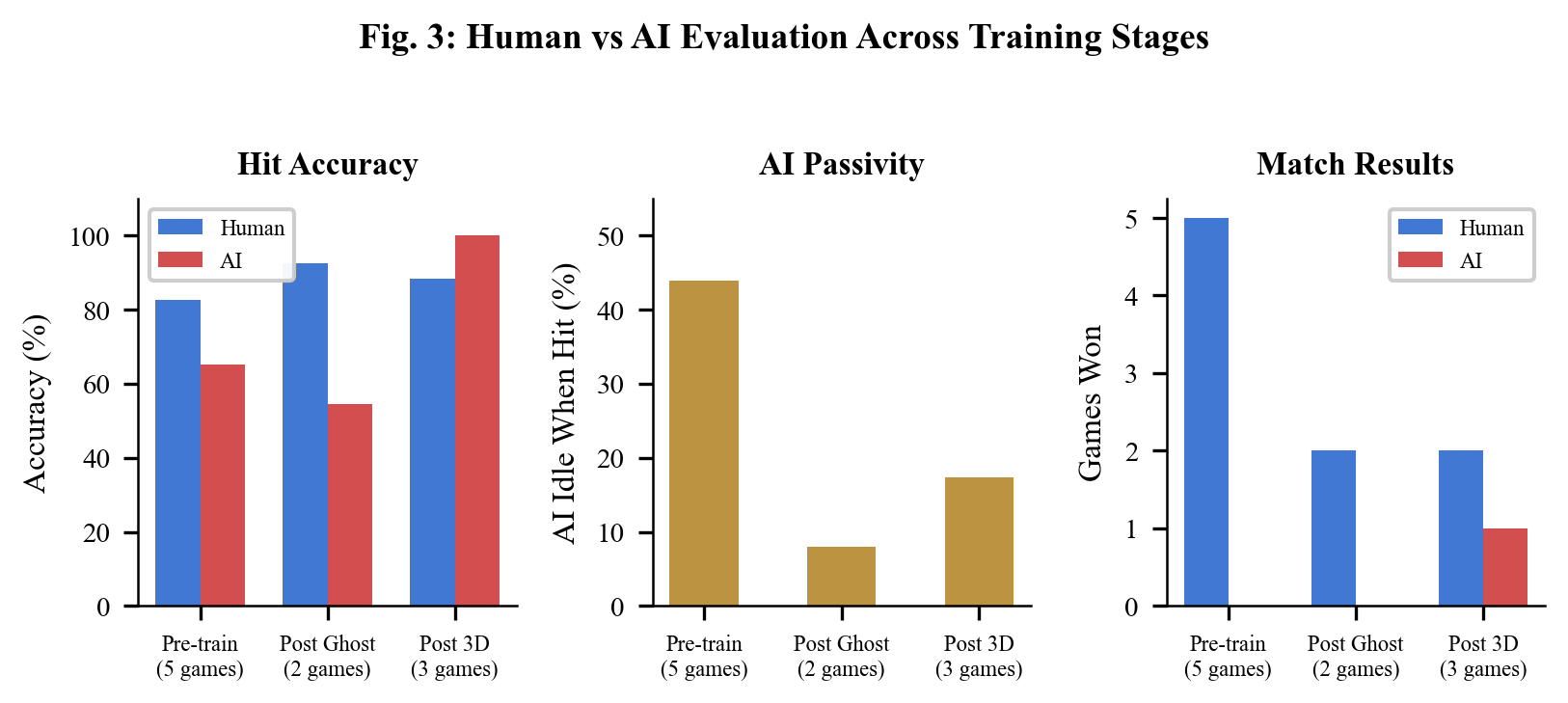
| Metric | Pre-Training | After 356 Rounds |
|---|---|---|
| AI ever beat me? | Never (0-5) | Yes (1-2) |
| AI accuracy | 65% | 100% (13/13) |
| AI idle when hit | 44% | 0% |
| AI damage per match | 53 | 128 |
The AI won its first match against me. In that game, it landed 13 consecutive attacks with 100% accuracy while I managed only 12 damage. Total damage across our 3-game set was exactly 248-248.
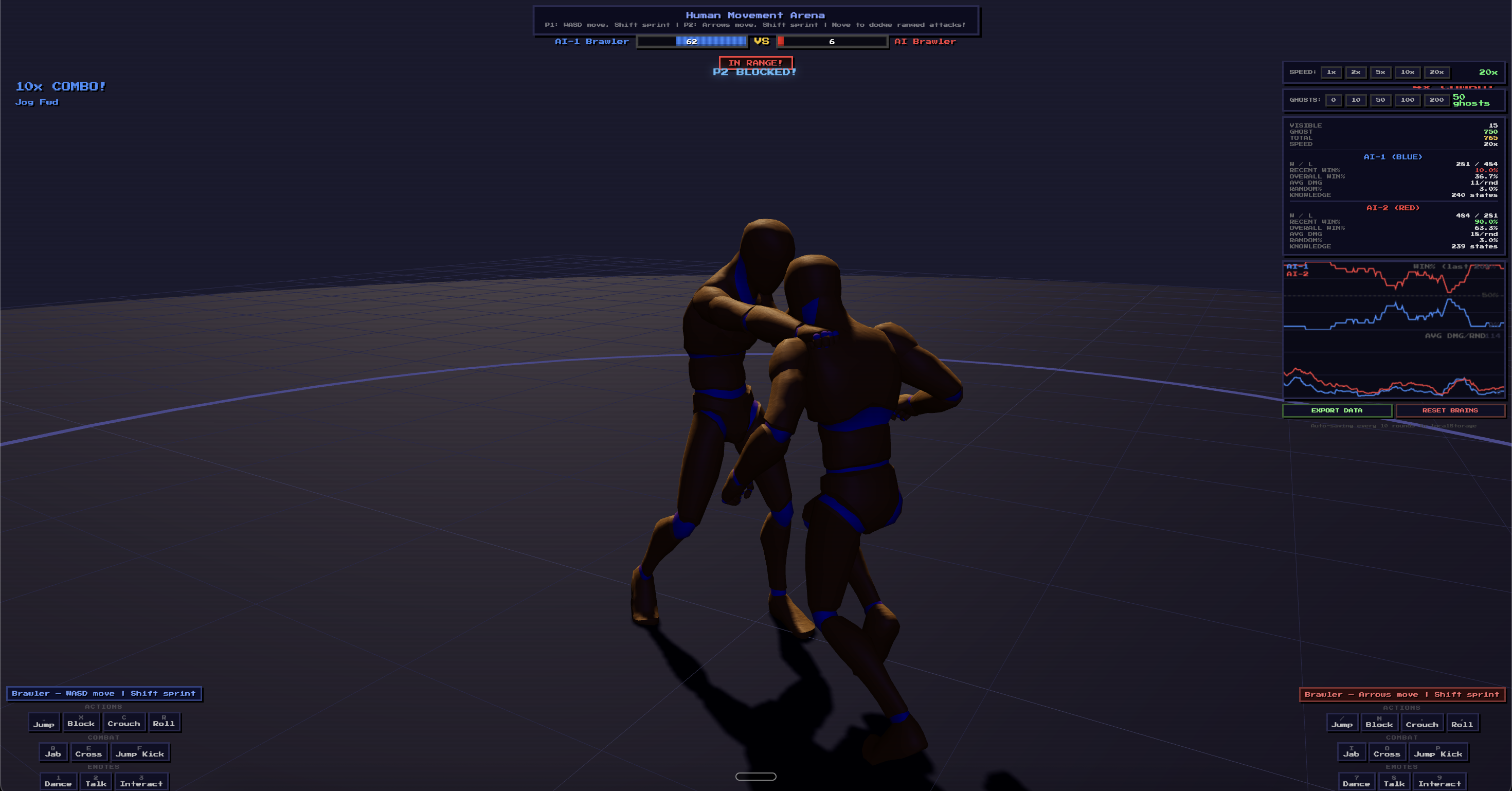
What the AI Learned
The Q-table reveals interpretable, human-like strategies:
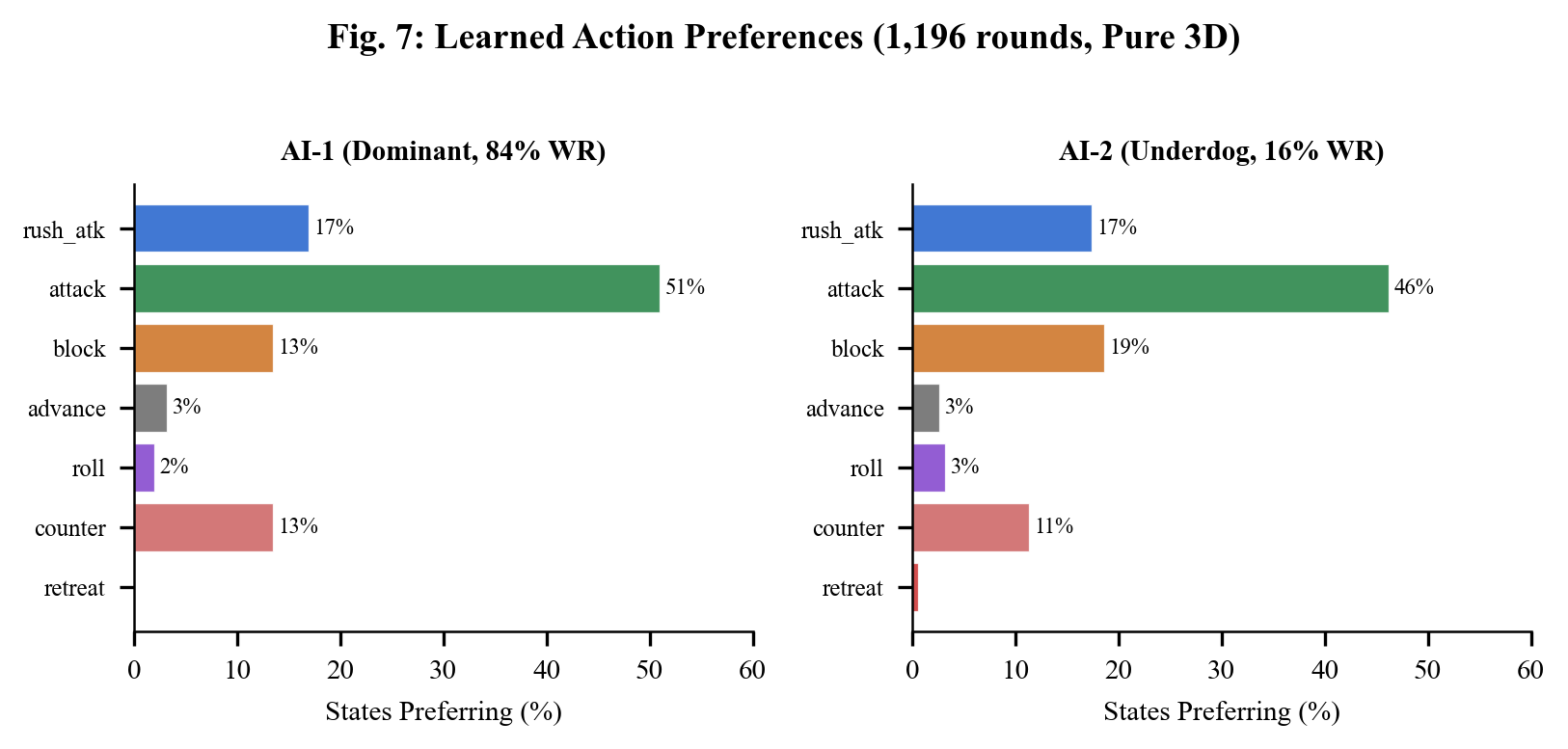
AI-1 (dominant, 84% win rate):
- Close + opponent idle → Attack (punish passivity)
- Close + opponent attacking → Counter (block then hit back)
- Far + opponent moving → Rush attack (close the gap)
- Overall: 51% attack, 17% rush, 14% counter
AI-2 (underdog):
- Developed a more defensive style with 19% blocking
- Uses counter when holding HP advantage
- 61% strategic divergence from AI-1 — they found different playstyles
The Numbers
- Total training rounds across all experiments: ~15,000
- Q-table size: 349 states x 7 actions = ~10KB
- No neural networks. No GPU. No Python. Just a browser.
- Key finding: Physics fidelity > training volume. Always.
Try It
Three modes:
- 1 Player — fight the trained AI (Easy / Medium / Hard / Expert)
- 2 Players — local multiplayer on one keyboard
- Train — watch two AIs fight and learn in real-time with speed controls
The full source code, training data, and research paper are available in the project repository.
Built in one session with Three.js, Q-learning, and a lot of reward function debugging.